
Tasavvur qiling, sizga katta loyiha topshirildi. Loyihani kattaligini sezishingiz uchun foydalanuvchilar soni 100 million ekanligi haqida ma'lumot oldingiz. Loyiha o'sib borayotgani xisobiga unga har kuni X ta yangi foydalanuvchilar qo'shilishadi. Sizga topshirilgan vazifa esa yangi foydalanuvchilar ro'yxatdan o'tish paytida ular kiritgan username bor yoki yo'qligini tekshirish.
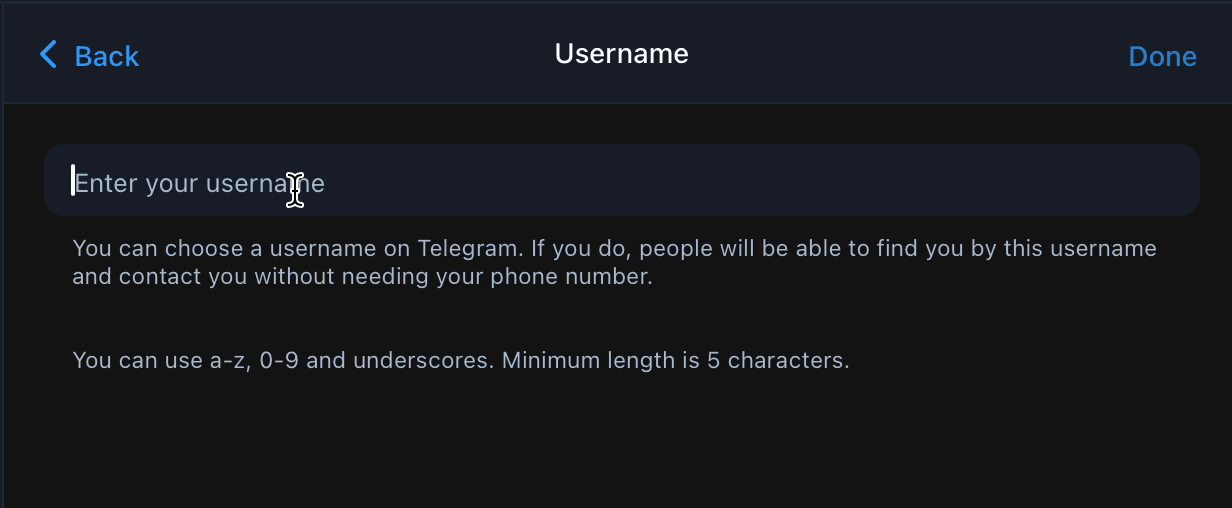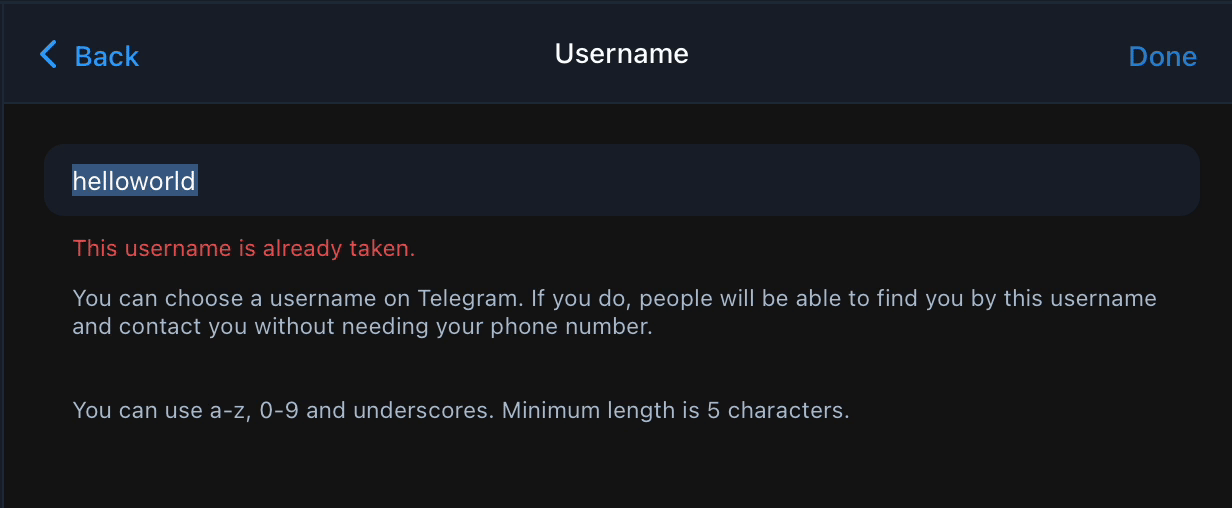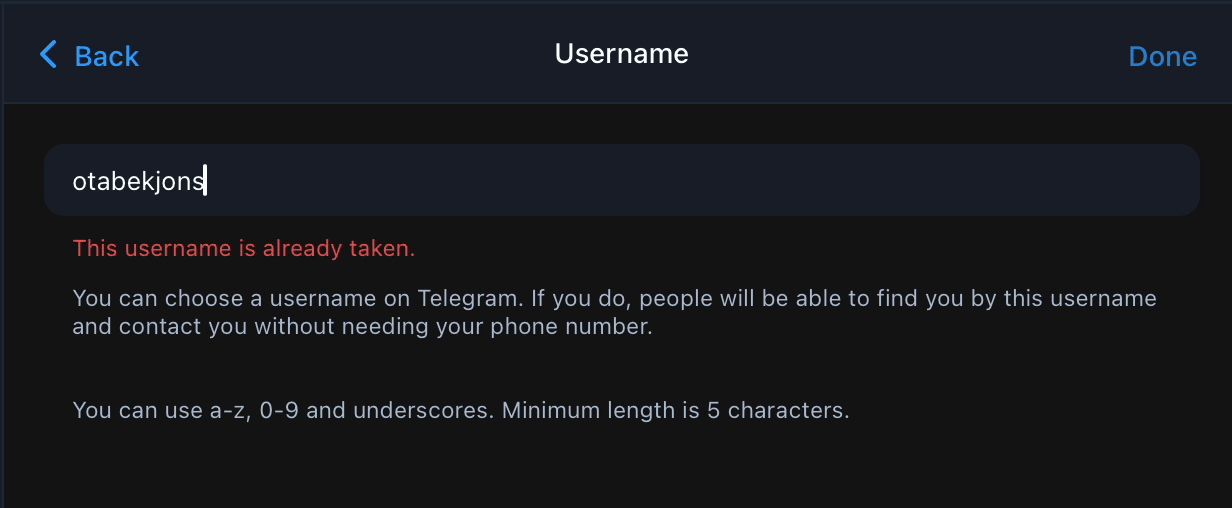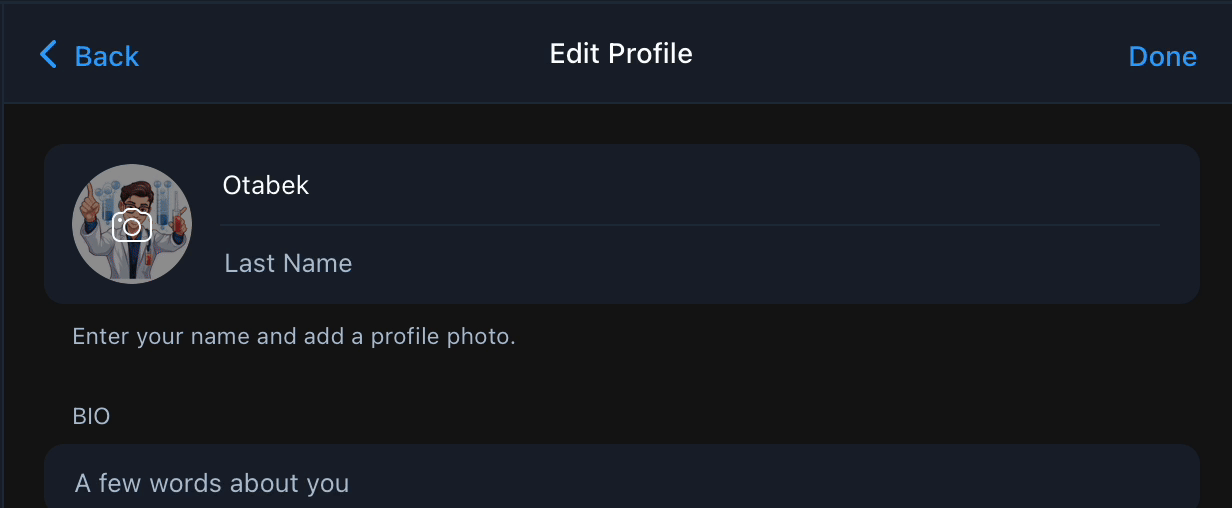
Agar sizni javobingiz tahminan shu query ko'rinishida bo'lsa shoshilmang. Ushbu post sizni dardingizga shifo bo'ladi va sizga qidiruvni O(n) dan O(1) tushirishni o'rgatadi. Xo'sh hikoya shunday boshlanadi ✨
Analysis
SQL ma'lumotlarni qatorma-qator tekshiradi va bu iterative yondashuv. Tekshirishdan oldin, ma'lumotlarni tezkor xotira (RAM)ga yuklab olishi ham kerak. Kompyuteringizdagi RAMni xajmi kichik bo'lsada, SQL yaxshi menejment qila oladi, ammo bu ma'lumotlarni yuklashdan to'sadi degani emas.
Tasavvur qiling, agar ma'lumotlar omborida 24 million foydalanuvchi bo'lsa, demak bizda 24 million qator (row) bor degani. Foydalanuvchilar soni o'sib borishni inobatga olsak, bizda kelajakda N ta qator bo'ladi O(n). Va har bir foydalanuvchi username tanlaganida N ta qatorni tekshirib keyin javob berish bizga qimmatga tushishi aniq. Bizga yaxshiroq yechim kerak, keling cachingdan boshlab ko'ramiz.
Caching

Keshlash (caching) kam o'zgaruvchi va tez-tez so'raluvchi ma'lumotlarga nisbatan qo'llanishi to'g'ri, ammo nega? Bloombergga o'xshagan online stock market qurayabsiz. Stock narxlari har sekund o'ynaydi. Agar siz o'sha sahifani cache qilsangiz, berilgan muddat oralig'ida foydalanuvchi cache ma'lumotni ko'radi, haqiqiy o'zgargan ma'lumotni emas. Cache doim tezkor xotirada saqlanadi shuning uchun ham serverlar keshlangan ma'lumotlarni tez qaytaradi.
Keshlash yaxshi yechim bo'lardikuya, ammo bizda ma'lumotlar millionta va bu kichik son emas. Qayndaydir jiprq foydalanuvchi tez-tez ism, familya va username o'zgartirib turishiga hech kim kafolat bermaydi. Va bu yechim unchalik yaxshi tanlov emas. Bizga tezkor qidiruv kerak.
Binary Search

Iterative yondashuv yaxshi yechim emasligini tushundik. Juda tezkor qidiruv algoritmlaridan biri bu Binary Search. Agar sizda 100 million ma'lumot bo'lsa atiga 27ta harakat bilan istalgan ma'lumotni topa olasiz va bu juda tez. Ammo Binary search to'g'ri ishlashi uchun ma'lumotlar tartiblangan bo'lishi kerak.
Yangi foydalanuvchi tizimdan ro'yxatdan o'tganida ma'lumotlar omoborini tartiblash uchun Quick Sort ishlatsangiz ham uning bahosi
Bloom Filter
Bloom filter - space-efficient probabilistic data structure xisoblanadi. Probabilistic data structure deyilayabdi ya'ni sizga aniq bir qiymat bera olmaydi. So'ralgan ma'lumot bor yoki yo'qlik ehtimoli qanchaligini ayta oladi ekan. Agar tizimingizda shunday ba'zi kichik qurbonliklarga tayyor bo'lsangiz albatta foydalanishni maslahat beraman.
Hashmap yoki Set istalgan elementni O(1) vaqtda topa olishi bizga ma'lum. Aynan shu O(1) tezlikni beruvchi mehanizm esa hashing xisoblanadi. Bloom filterni asosida hashing algoritmlari bo'lgani uchun ham qidirishga O(1) vaqt sarflaydi. Va hashmap dagi kabi hash collision muammosi bu yerda ham bor faqat uni nomi false positive. Ammo false negative hech qachon bo'lmasligiga kafolat beriladi. Bu so'zlarni ham hozir gapirib beraman.
Implementation

Sizga N uzunlikdagi bit Array kerak bo'ladi misol uchun yuqoridagidek. Boshida uning barcha qiymatlari 0 ga teng bo'lishi kerak. Keyin yaxshi hash funksiya tanlashingiz kerak, qancha yaxshi bo'lsa shuncha kam collision bo'ladi va tez xisoblaydi.
Hash funksiya sizdan qiymat olib son qaytaradi. Siz hash funksiya bergan sonni bit Array uzunligiga bo'lasiz. Chiqgan natija esa yuqoridagi bit Arrayni qaysi katakchasiga borib yozish yoki tekshirish kerakligini anglatadi. Agar falonchi nomli username tizimda bo'lsa bit Array sizga 1 sonini bo'lmasa 0 qaytaradi.

False Positives
Tasavvur qiling bizni hash funksiyalarimiz hash("otabek") va hash("chris") bir xil qiymat qaytardi. Tizimga birinchi bo'lib otabek ro'yxatdan o'tdi. Keyin chris username bor yoki yo'qligini tekshirib ko'rdi va qarasa allaqachon olingan deb aytayabdi. Aynan shu holatda False Positive deyiladi.
Bungan qochish uchun siz bir emas bir nechta hash funksiya ishlatishingiz kerak bo'ladi. Bu ham yetmaganidek nechta hash funksiyangiz bo'lsa, har bir foydalanuvchi shuncha joy olishi kerak ham degani. Pastdagi rasmda biz 3ta hash funksiyasini tasvirlaganmiz.

Undan tashqari False positive ehtimolligni tekshirish uchun ham mahsus matematik formulalar bor, bu qismini sizga qoldiraman. Ammo asosiy tushunchalarni tushundingiz degan umiddaman.
Conclusion
Iterative O(n) yechimlar doim yomon deyish noto'g'ri va O(1) yechim doim ham zo'r degani emas. Siz doim dastur holatidan kelib chiqib qarorlar qilishingiz kerak bo'ladi. Ushbu postning maqsadi esa sizga Bloom filter qachon va qanday yaxshi ishlatilishi mumkinligini tushuntirish edi.
Kelasi postlarning birida ba'zan Iterative yechim Constatnt yechimdan yaxshiroqligini ko'rsatib o'tishga ham harakat qilaman. Postni bo'lishib o'ting, ko'plab insonlar rivoji uchun xissa qo'shing (pastdagidek bo'lishmang).

Bloom Filter Viktorinasi
Bloom Filter ma'lumot strukturasi haqida bilimingizni tekshiring
Question 1 of 6
Bloom Filter qanday data structure hisoblanadi?

